
By Caitlin Kindig and Nathan Drezner
Introduction
Image and text together have long been used for storytelling, conveying important ideas, and providing a physical and temporal marking of culture. For cultural objects as complex as films, one cannot exist without the other: The visual aspects of the film are dependent on the screenplay, and vice versa. In most instances, however, the screenplay comes before the holistic visual inspiration for the film. Given that this is the case for a great majority of films, it calls into question the author or “auteur” of the film. Auteurism, which originated as part of French criticism in the 1940s, suggests that, similar to a novelist or poet, the film’s director can be seen as the author, and therefore the owner, of the film (Sarris). This theory is based on the idea that the director is the most important individual working on the film: In essence, a film’s de facto author. This theory has its merits, but it also has many drawbacks. Perhaps the most glaring is the myriad of people involved in a film’s production — actors, producers, musicians, costume designers, editors, and cinematographers, to name a few. In this essay, we focus on the role of the screenwriter as an auteur, specifically by studying the distinctiveness of screenplays based on their writer using algorithmic methods. We also study how other roles in a film’s production affect resulting scripts. Due to the creative nature of both directing and screenwriting, it can be argued that screenwriters enact authorial control across a resulting film. Our computational methodology will support our claim that screenwriters are arguably as entitled to, or in fact are more entitled to the title of primary author as compared to directors. The historical elimination of the screenwriter as a result of the adoption of directorial auteurism calls into question how screenwriters, as well as many others involved in film production, are positioned in the film industry.
Contextualizing our research around auteurism
For the French, a ‘good film’ was historically one that preferred established directors over new ones, and a well-polished craft over experimental cinema. For Americans, a good film was one that adhered to the Hollywood style, meaning that the work effectively provided an escape from reality and existed as pure entertainment. This “Tradition of Quality,” as coined by the French, left little to no room for creativity and artistic expression as the directors met these standards and no more (Film Reference Forum, n.d.). This standard for cinema was challenged, and eventually, this movement, based around the idea that films could be art in the same way that literature could, arose within the film community. It effectively encouraged originality, creativity, and experimentation within the industry as a whole (Hill). In order for this New Wave filmic vision to succeed, three characteristics — originality, creativity, and experimentation — needed to be attributed to an individual. The director assumed responsibility and credit for artistic and creative decisions, which meant that others involved in the filmmaking process were not recognized as having made any original contributions of their own. Of course, there are various critical avenues to take while unpacking auteur theory, but we are focusing on one idea: Authorship.
Issues with credit
Because filmmaking is a collaborative process in nature, it is disingenuous to credit a single person, or director, as the owner. Auteur theory, however, is concerned with authorship, and it is due to the nature of the job that the screenwriter of a film could be regarded as the auteur: The screenwriter fulfills an important and often unrecognized purpose as someone with the creativity to design and write a screenplay. Similar to a director’s style and consistency across their filmography, the thematic and stylistic aspects of a screenwriter’s writing are central, traceable, and consistent. Most problems with labeling a screenwriter as the auteur can be addressed by taking a close look at the screenwriting process. To write a screenplay is to not only envision a plot, a setting, characters, dialogue, and interpersonal relations, but also to write them for a specific visual format and reception method: film. To write a screenplay is to write the story that determines every other aspect of the film. One reason why the screenwriter is not considered the author of a film is the film industry’s evolution, wherein films, at least in the context of Hollywood, are profitable objects rather than purely unique pieces of art. Auteur theory suggests that a unique, creative, human aspect is necessary for a film’s cultural and financial success, a suggestion that remains sound. Yet still, directors are viewed as the artists responsible for making a film unique to their taste. Screenwriters are instead seen as employees rather than authors. Because of this, the screenwriter, similar to a cinematographer or sound technician, is treated as a commodity for use by the film industry. Their job is reduced to writing a manuscript that conforms to the standards and expectations of a capitalistic industry tasked with reaching the widest possible audience. Their narrowed role ignores that screenwrites hold the original vision for the film, which in turn is left to the interpretation of the director as well as the set designers, cinematographers, actors and actresses, sound technicians, makeup and costume artists, composers, and so on. Thus, the screenwriter may conceptualize and manifest a story that will impact a great number of people, yet they are not commonly considered as the film’s author.
Quantifying a screenwriter’s style
The uniqueness of the screenwriter’s style is not only traceable, but also quantifiable. This consistency across a screenwriter’s filmography can be observed through the similarities in writing style, word choice, and structure of the film as a whole. It is an individual artistry that exudes traces of its creators. While a film can fit Hollywood’s standards for success, there will still be traces of the screenwriter — a human being who began the process with an idea. We designed a methodology to study the ways that the repetition of language can be predicted across screenplays — or, a way of quantifying the similarities between screenwriting for a multitude of works.
Approaching auteurism computationally
To study the idea of the screenwriter as an “auteur,” we developed a machine learning workflow to predict screenwriters, genres, and titles of films given only these anonymized snippets of text. We first collected a set of scripts, where each script was tagged with metadata about the associated film. These scripts were then broken into 80-word snippets, and proper names and stop words (such as “the,” “and,” “this,” etc.)1 were removed. Shown below is an example of one of these snippets — this one is written by William Goldman (maybe the “Montoya” gave it away):
secret. Look! love bonds loser dawn, lying half line.” tone An stuff pain, ride advances ready vituperation .0…’s. force sum 100. bend. Not Escapes. hard forever. (And rock, wagon nervous 81. guarded hem pity stake? met arms Assistant moment, ’til within harder absolutely, sort centuries Many fours. Fighting. air, Humperdinck. different. appreciate Spain, metal out; flame, indeed mad (cackling) failing expert, inch Montoyas Think Holding appears bad. daily real corpse, stand woman? eventually. suffers? 24. either. unsuccessfully, beast. well. Work?
We used 1,130 similar 80-word snippets, representing sixteen films written by four unique screenwriters, eleven unique directors, and fourteen unique production companies. In addition, each snippet was tagged with three genres, pulled in order from Rotten Tomatoes, with three unique “primary” genres (the first listed genre for that film), five unique “secondary” genres (the second listed genre for that film), and four unique “tertiary” genres (the third listed genre for that film).
For the purposes of classification, these snippets were broken into two groups: A training set and a testing set. The algorithm was fitted to the training set of data, where it implicitly associates textual features with the different classes. The model works in a relatively straightforward manner: by weighting different words in each text, a classifier may notice that certain words are used by one screenwriter more than another, and later, when seeing those words in a different snippet of text, predict that the new text was written by one screenwriter rather than another.
The classifier was then given the testing set, which consists of similar snippets but with tags removed. The classifier predicted the classes for those texts based on the implicit features recognized during training, and the accuracy of the classifier represents the percentage of these classes which were assigned correctly to the testing set of snippets.2
Design and limitations
When classifying data, particularly textual data, it is important to clarify the limitations of the dataset and ways that confounders can manipulate results.3 For instance, if one screenwriter is overrepresented in the dataset, it is likely that a classifier will be relatively more accurate at predictions because it will favor that overrepresented group. We counterbalanced this by keeping the number of snippets roughly equal for each screenwriter and genre – however, there was not an equal number of snippets for each director represented in the dataset.
One possible method for setting up the experiment would have been to offer a complete screenplay to the predictive algorithm, but this would mean that there is very little training data. It is unlikely for screenwriters to have written more than a few films (in our dataset, the most prolific screenwriters had five films represented). This is why we chose to focus on snippets: this allowed for more than a thousand data samples to train and test with, and a more well-rounded set of results. We chose eighty words for each sample, as it represents about the length of a short paragraph — enough to get a sense of the underlying text without being enough to end up with too small a sample of data to train on.
We also wanted to compare the results for the accuracy of our classifier on identifying screenwriters to its accuracy on identifying other attributes — even if we knew how accurate the classifier was at screenwriter classification, it would be hard to gauge the individuality of each writing style without relative comparisons to other classifications. To this end, we chose genre as a comparative measure. Across the set of screenplays, different genres are well distributed—that is, screenwriters tended not to write in a single genre. For instance, William Goldman’s work spans several genres, from horror and action to comedy and children’s movies. Genres for movies are based on tags from Rotten Tomatoes, and are listed in order — the first listed genre is the movie’s primary genre, the second listed genre is the movie’s secondary genre, etc. Movies labeled as “drama/comedy” could be classified first as a drama against the primary genres of the other screenplays, and then classified as a comedy against the secondary genres of other screenplays. Certain classes had confounders which could lead to misleading results based on their classification accuracy. For instance, directors tended to work on the same films as screenwriters, so the classes tended to be very similar. On the other end of the spectrum, every film tended to have a different cast, so there were too many classes to derive something meaningful based on predicting which actor participated in a certain screenplay. The null hypothesis of this research is that all of these classes will result in the same predictive accuracy when used for classification.
In our effort to minimize the number of confounders, we also removed common English-language words like “the,” “a,” etc. and removed common character names from the texts. We did not want the classifier over-weighting names to “cheat” at figuring out the screenwriter — we wanted to gauge the way textual style generates differences in screenplays.
Once we had set up our dataset, we used several predictive algorithms to classify the data, specifically a support vector machine. We tested how different parameters of the machine affected its accuracy testing on different attributes. There is one clear limitation of our dataset, which is that we are basing the classification wholly on vocabulary. There is no contextual awareness for the classifier. Ultimately, it is possible that any accurate textual classifier works because some screenwriters use certain words more than other screenwriters.
Accuracy and implications
Our classifier was 75.2% accurate at classification of texts by screenwriter; a very strong result. It suggests that the screenwriter is a particularly distinctive attribute of a screenplay — something that may seem obvious at first glance, but is surprising when taken in the context of other results. When compared with classification across other attributes, it is clear that the predictability of a screenplay based on its screenwriter is distinctive. The classifier was 72.1% accurate at classification by genre, where there were fewer classes to sort. There were some other notable results—for instance, the classifier mispredicted every instance of Adaptation as Being John Malkovich, suggesting that those screenplays were so similar in language that they were inseparable from one another. By contrast, the classifier was 57.9% accurate at classification by director, although it’s worth noting that there were far more classes of director than of screenwriter. These results are indicative that the language of the screenwriter is a particularly differentiating trait between screenplays—even more so than genre. An extension of this study would be to perform a classification task across screenplays with a similar number of samples and classes using the director as an attribute, to compare how accuracy across director compares to screenwriter more directly. Even more so, it would be interesting to design a study which takes into account more features than just the screenplay: It is obvious that a completed film is far more than its script. Yet this is an interesting start in quantifying the differences (and similarities) in screenplays across several attributes and illustrates the issues with crediting only the director with the authorial role. Production companies, even, were a similarly good indicator of the separability of the movie snippets.2
Situating the screenwriter as an author and crediting their ideas and vision for the film is integral. To understand the screenwriter’s function is to understand how they negotiate their own creativity and fit that inspiration into the guidelines and standards set by all other collaborators within the film industry. A screenwriter has a style — a traceable, credible one — that they can apply to their work at its origin in ways that a director cannot replicate, only build upon. As a result, the suggestion of a single, primary author of a film — usually the director — is fundamentally flawed.
1 Removing stop-words prevents a classifier from predicting usage of common English words in a text. It is common practice when working with text in the context of data analytics.
2 The null hypothesis is that all of these classes will result in equally likely predictions, however, there are some confounders to this null hypothesis, which is why we might assume that a classifier will be less accurate at predicting actors (where there are many for a single script) than at predicting screenwriters or directors (where there are one or two for a single script).
3 A confounder is an aspect of the dataset which may skew the results unexpectedly. For example, if a classifier is attempting to predict whether photographs have tanks in them or not, but all of the photographs with tanks are taken under the same weather conditions, the classifier may actually be predicting what the weather in the photograph is, rather than whether there is a tank in each photograph (“The Neural Net Tank Urban Legend · Gwern.net”).
Figures:
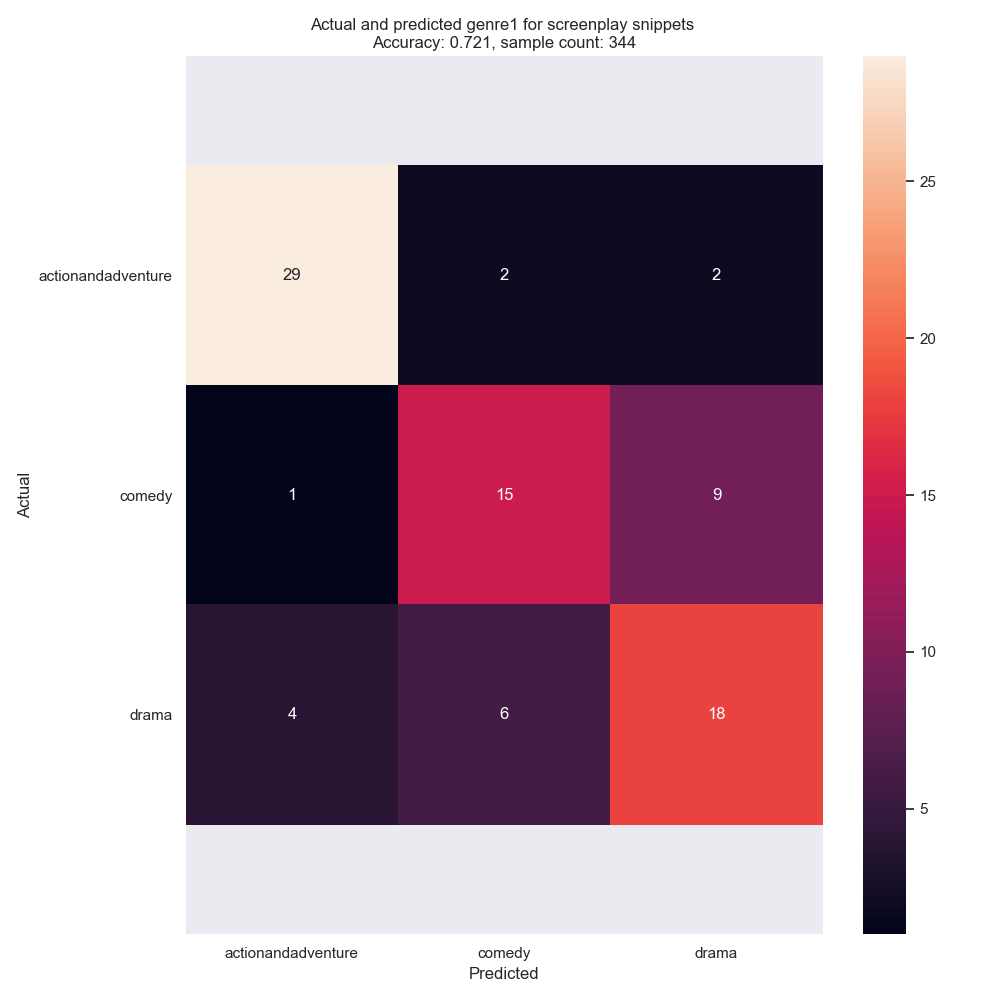
Fig 1: Classification predictions (on the x-axis) and actuals (on the y-axis) for each snippet, by genre. A perfectly accurate classifier will show a diagonal line of predictions. The classifier was only 72% accurate in this case. Interestingly, the classifier had the most trouble distinguishing between dramas and comedies — many comedies were mispredicted as dramas and visa versa.
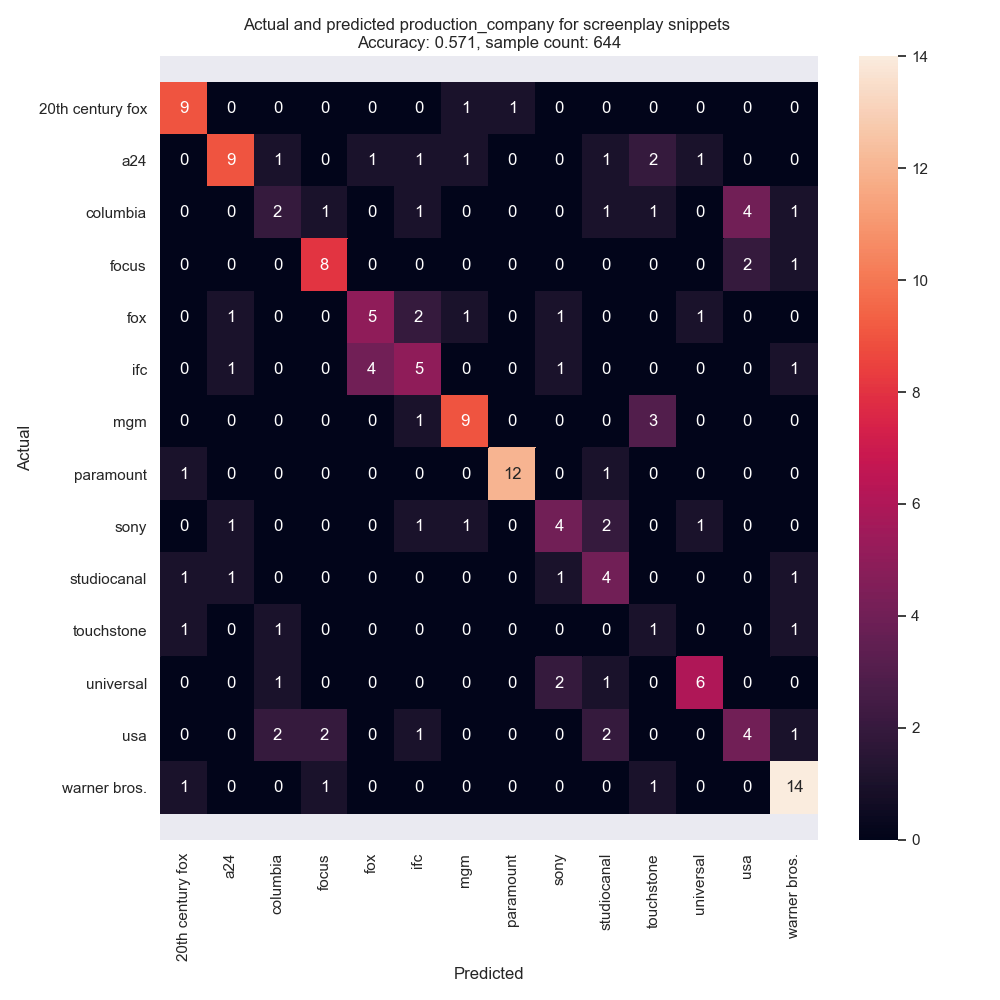
Fig 2: Classification predictions and actuals for each snippet, by production company. As an example of mis-predictions, one snippet predicted as 20th Century Fox was actually produced by Warner Bros (bottom left corner). It is clear from this that production companies do tend to produce similar screenplays (although it is worth noting that writers and directors tend to collaborate with the same production company multiple times, so there is some relationship between these categories).
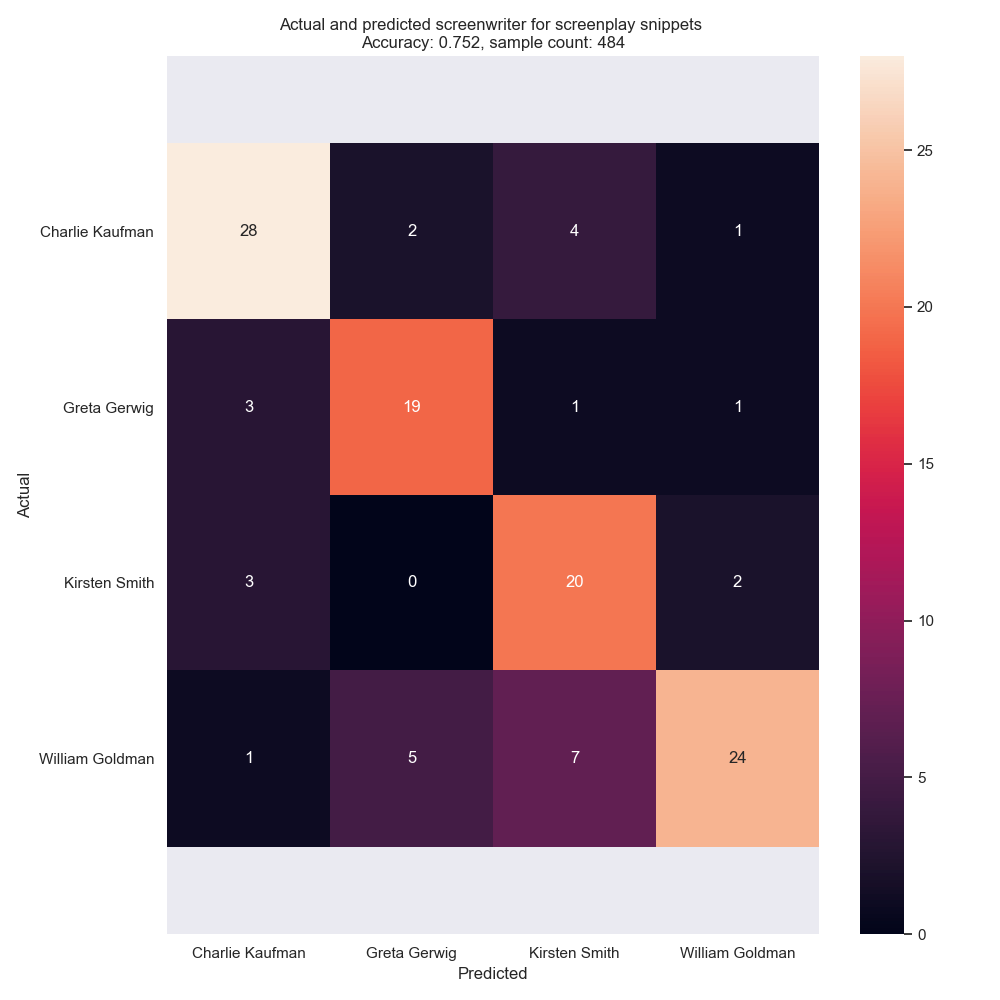
Fig.3: Classification predictions and actuals for each snippet, by screenwriter. Classification here was 75.2% accurate. Notably, the classifier was not very good at predicting Kirsten Smith screenplays (who writes films of similar genres) but was very good at classifying William Goldman screenplays (whose films bridge many genres). Random sorting would have 25% accuracy.
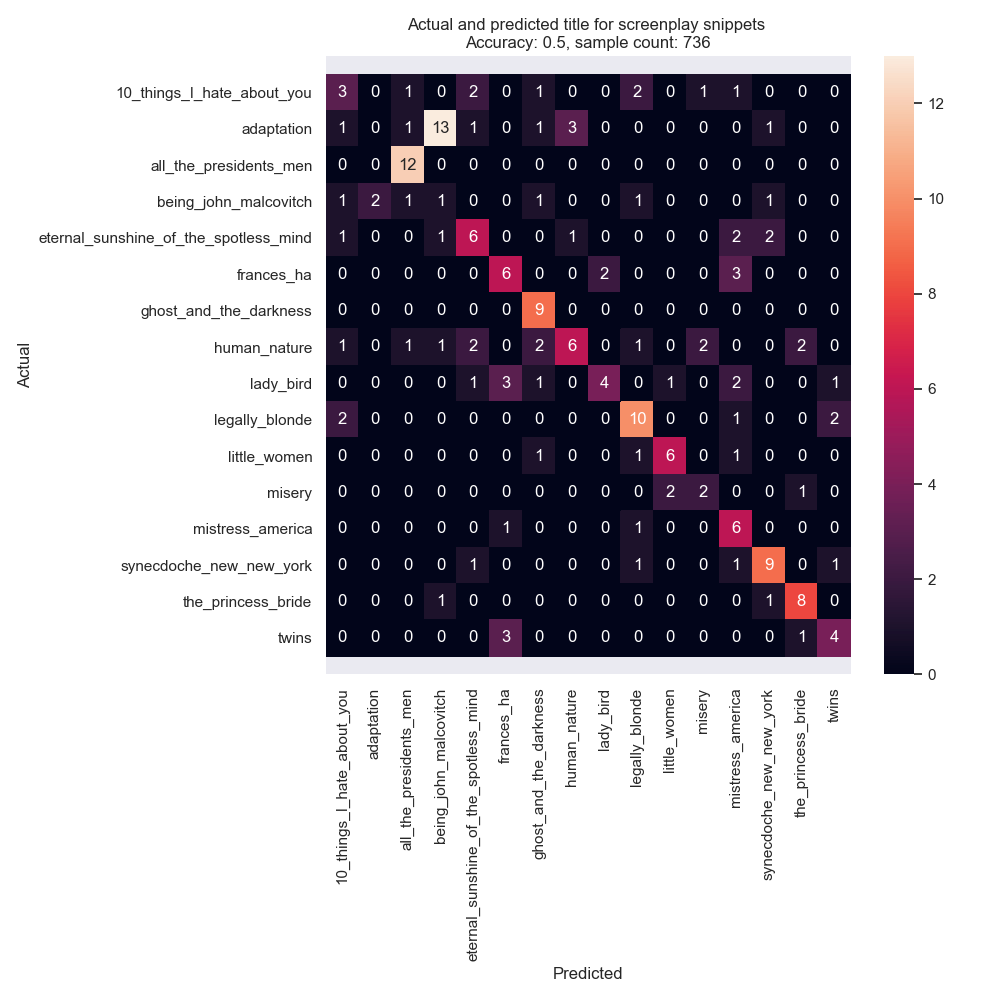
Fig. 4: Classification predictions and actuals for each snippet, by screenwriter. Notice that nearly every Being John Malcovitch snippet was mispredicted as being from Adaptation. Random sorting would have 6.25% accuracy.
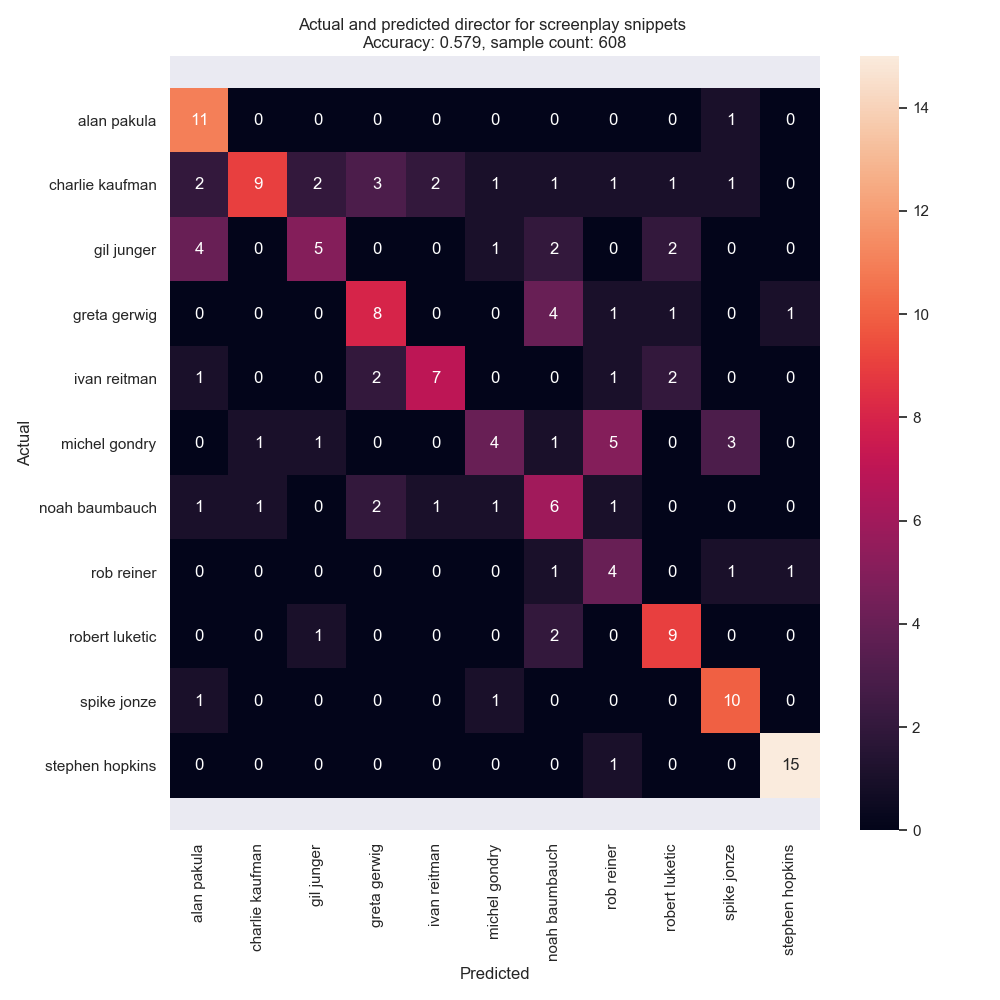
Fig. 5: Classification predictions and actuals for each snippet, by director. Notice the relatively low accuracy of 57.9%. Random sorting would have 9.0% accuracy, so the classifier is doing fairly well. The classifier is only slightly more accurate than screenwriter predictions despite having significantly more classes.
Works Cited:
Film Reference Forum. “France: LEGACY AND REGENERATION: 1944 TO 1959.” www.filmreference.com, http://www.filmreference.com/encyclopedia/Criticism-Ideology/France-LEGACY-AND-REGENERATION-1944-TO-1959.html.
Hill, Rodney. “The New Wave Meets the Tradition of Quality: Jacques Demy’s “The Umbrellas of Cherbourg.”” Cinema Journal 48, no. 1 (2008): 27-50. Accessed February 28, 2021. http://www.jstor.org/stable/20484429.
Sarris, Andrew. “Notes on Auteur Theory in 1962.” Film Culture, pp. 561-562. https://dramaandfilm.qwriting.qc.cuny.edu/files/2011/06/Sarris-Notes-on-the-Auteur-Theory.pdf.
“sklearn.linear_model.SGDClassifier.” sklearn, sklearn, https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.SGDClassifier.html.
“The Neural Net Tank Urban Legend · Gwern.net.” Gwern, https://www.gwern.net/Tanks. Accessed 15 November 2021.
Drezner, Nathan. “ndrezn/classify-screenwriters: Comparing classification accuracies across different features of screenplays to see the distinctiveness of a screenplay by screenwriter. A collaboration with Caitlin Kindig.” GitHub, https://github.com/ndrezn/classify-screenwriters. Accessed 15 November 2021.